













 JavaEE
JavaEE 鴻蒙應(yīng)用開(kāi)發(fā)
鴻蒙應(yīng)用開(kāi)發(fā) HTML&JS+前端
HTML&JS+前端 Python+大數(shù)據(jù)開(kāi)發(fā)
Python+大數(shù)據(jù)開(kāi)發(fā) 人工智能開(kāi)發(fā)
人工智能開(kāi)發(fā) 電商視覺(jué)設(shè)計(jì)
電商視覺(jué)設(shè)計(jì) 軟件測(cè)試
軟件測(cè)試 新媒體+短視頻
新媒體+短視頻 集成電路應(yīng)用開(kāi)發(fā)
集成電路應(yīng)用開(kāi)發(fā) C/C++
C/C++ 狂野架構(gòu)師
狂野架構(gòu)師 IP短視頻
IP短視頻


深入理解字符流的編碼
更新時(shí)間:2018年12月19日14時(shí)59分 來(lái)源:傳智播客 瀏覽次數(shù):
Java中是以流的形式來(lái)實(shí)現(xiàn)數(shù)據(jù)在網(wǎng)絡(luò)中的傳輸,而所說(shuō)的“流”則是字節(jié)流。因?yàn)樗械臄?shù)據(jù)的最底層都是以字節(jié)為單位存儲(chǔ)的,所以以字節(jié)為單位傳輸數(shù)據(jù)無(wú)疑是最簡(jiǎn)單也是最有效的傳輸方式。
我們?cè)趯W(xué)習(xí)Java的過(guò)程中,也經(jīng)常接觸字符流,字符流顧名思義則是以字符為單位進(jìn)行數(shù)據(jù)傳輸,但是其實(shí)字符流的應(yīng)用面是很窄的,并不是所有的文件都存在字符的概念的,比如視頻文件、音頻文件、圖片文件,這些是無(wú)法以字符為單位進(jìn)行傳輸?shù)摹W址髦荒軐?duì)文本字符進(jìn)行操作。
提到字符,我們首先就會(huì)想到的是編碼,因?yàn)橛?jì)算機(jī)存儲(chǔ)的是字節(jié),我們看到的卻是字符,這之間是靠編碼表對(duì)應(yīng)起來(lái)的,那么這也就是本篇文章索要研究的內(nèi)容—字符流編碼。
首先我們來(lái)看下面的案例:
案例顯示,Demo.java的項(xiàng)目編碼和b.txt的編碼格式一樣,則能夠正常寫(xiě)入,不會(huì)亂碼。原理如下圖所示: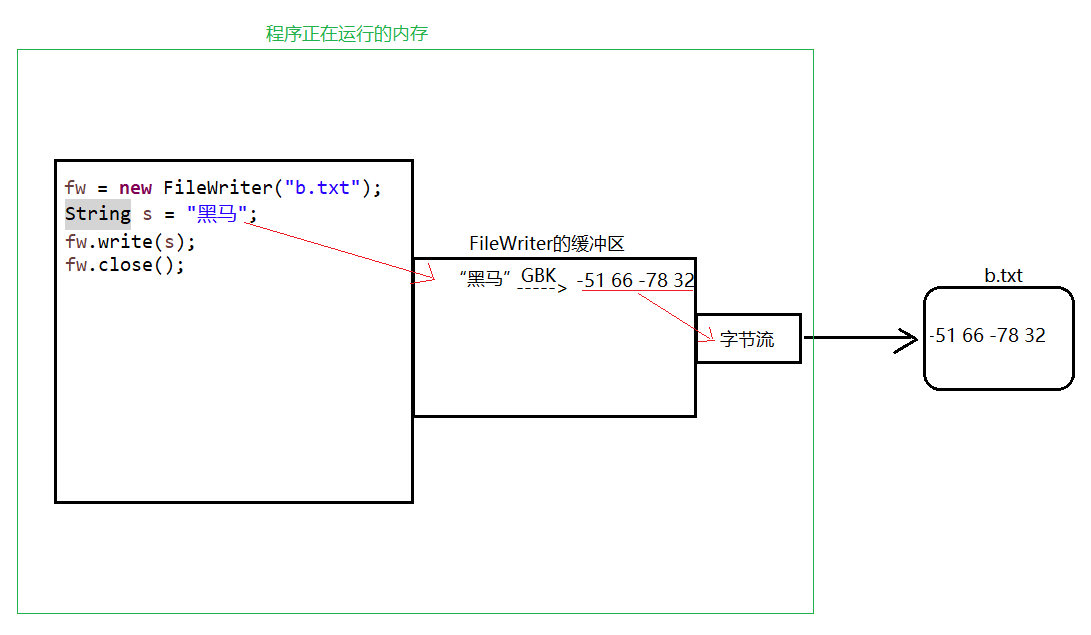
字符流,每一個(gè)字符流都存在一個(gè)緩沖區(qū),緩沖區(qū)的編碼格式是和項(xiàng)目的編碼格式一致的,上述代碼執(zhí)行流程是:字符串“黑馬”在FileWriter的緩沖區(qū)里面通過(guò)GBK編碼把漢字編碼成對(duì)應(yīng)的字節(jié),然后底層通過(guò)字節(jié)流將字節(jié)寫(xiě)入到b.txt。 很多人我們打開(kāi)b.txt時(shí)看到的是“黑馬”這兩個(gè)字啊,并不是什么碼值啊。其實(shí)所有文件的底層都是字節(jié),子不過(guò)我們打開(kāi)b.txt時(shí),記事本軟件就通過(guò)此文件的編碼—GBK幫我們把碼值解碼成“黑馬”這兩個(gè)字了,所以我們看到的是黑馬。照這樣看來(lái),如果b.txt的文件編碼是UTF-8的話,肯定就會(huì)亂碼,因?yàn)橛浭卤緯?huì)按照UTF-8進(jìn)行解碼,效果如下圖所示: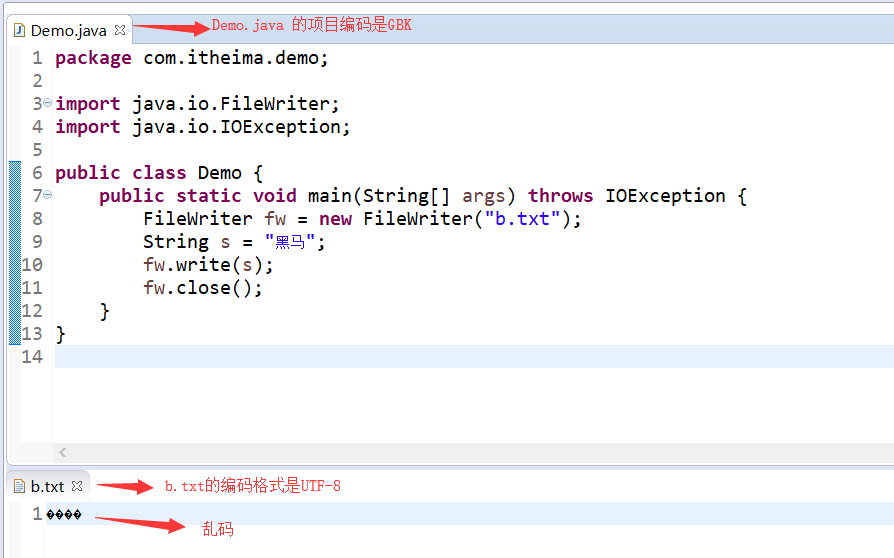
接下來(lái)難點(diǎn)才真正的來(lái)臨(很多人看了下面的代碼和運(yùn)行效果就蒙圈),我們把上圖的代碼改下(其他編碼格式不變),你會(huì)發(fā)現(xiàn)不亂碼了,如下圖:
[Java] 純文本查看 復(fù)制代碼
|
01
02
03
04
05
06
07
08
09
10
|
public class Demo {[/align] public static void main(String[] args) throws IOException { FileWriter fw = new FileWriter("b.txt"); String s = "黑馬"; byte[] bytes = s.getBytes("UTF-8"); String s1 = new String(bytes); fw.write(s1); fw.close(); }} |
很多人蒙圈的原因是因?yàn)椋劝炎址D(zhuǎn)為了UTF-8 但是又通過(guò)new String(bytes)轉(zhuǎn)成了GBK啊,但是b.txt是UTF-8格式的編碼啊。為什么沒(méi)有亂碼呢? 下圖解釋的很詳細(xì):
執(zhí)行流程是:先通過(guò)UTF-8編碼把“黑馬”編碼成幾個(gè)字節(jié)比如13 42 35 86 59 47,然后再通過(guò)GBK編碼,把該碼值解碼成對(duì)應(yīng)的字符比如“傳智人”,然后“傳智人”進(jìn)入緩沖區(qū)會(huì)通過(guò)GBK編碼編碼成剛才的字節(jié) 也就是13 42 35 86 59 47,然后再通過(guò)字節(jié)流寫(xiě)入到b.txt中,當(dāng)打開(kāi)b.txt時(shí),記事本軟件會(huì)按照此文件編碼格式-UTF-8解碼成“黑馬”,所以我們看到的是沒(méi)有亂碼。
總結(jié):通過(guò)比價(jià)復(fù)雜的案例我們明白了一、每個(gè)字符流都存在緩沖區(qū),而且緩沖區(qū)的編碼是和項(xiàng)目編碼一致。二、字符流的底層依然是使用的字節(jié)流,而且還存在緩沖區(qū)的編碼動(dòng)作,所以效率比字節(jié)流會(huì)慢很多,所以通常數(shù)據(jù)的傳輸我們都會(huì)使用字節(jié)流。三、文本文件的底層存儲(chǔ)的也是字節(jié),我們打開(kāi)文件看到的字符,是記事本軟件所做的解碼。
首發(fā):http://java.itcast.cn
最新資訊
0
分享到:



文章列表.jpg) javaee
javaee
科列表頁(yè)面右側(cè)廣告圖.jpg) python
python
 web
web
 design
design
據(jù)學(xué)科列表頁(yè)右側(cè).png) cloud
cloud
 test
test
 c
c
 netmarket
netmarket
 pm
pm
 Linux
Linux
 movies
movies
 robot
robot
 uids
uids
 Python
Python
 jdbc
jdbc

北京校區(qū)
江蘇傳智播客教育科技股份有限公司 版權(quán)所有Copyright 2006-2024 All Rights Reserved 蘇ICP備16007882號(hào)營(yíng)業(yè)執(zhí)照增值電信業(yè)務(wù)經(jīng)營(yíng)許可證出版物經(jīng)營(yíng)許可證 蘇公網(wǎng)安備 32132202001156號(hào)
蘇公網(wǎng)安備 32132202001156號(hào)